OAuth for Dummies [Part 1] Why OAuth
❕ This is Part 1 of a two-part blog series on OAuth.
Part 1: Why OAuth focuses on the need for OAuth.
Part 2: OAuth in Detail goes deep into the workings of OAuth.
Introduction
Are you someone who has heard about the buzzword OAuth, but never seemed to understand it fully? Or heck, even someone who understands OAuth, but never had the time to dive into why there was ever a need for this complex yet powerful framework? Then you are at the right place.
In this post, I am going to cover how OAuth evolved and what were some limitations that developers have faced throughout history.
Before we proceed, let’s clear up on some basics first.
Authentication
Authentication is the process of verifying identity. It helps confirm that people are who they say they are. It deals with login IDs and passwords.
Authorization
Authorization is the process of verifying what someone is allowed to do. It deals with permissions and roles associated with entities.
The Problem
Let’s consider the problem of API Authorization. We all have seen an option like this on various sites:

How exactly is an application allowed access to an API? Let’s say the API is responsible for sending an email on behalf of the user. That said, we wouldn’t want the application to perform other tasks like reading or deleting emails on the user’s behalf.
There exist a few solutions with which this can be achieved, let’s go through them one at a time.
Solutions
(1) Credential Sharing
The simplest solution is asking the user with the credentials to the API using a form like this:
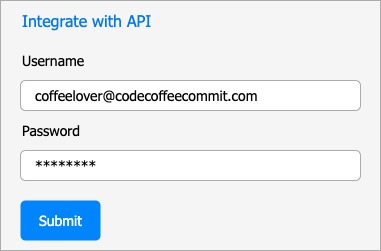
There are a couple of issues associated with this method.
Issue #1: Impersonation
The application is impersonating the user. There is no way to know the difference between the application and the user. Because of this:
- We lose the ability to restrict access to the application. Instead of only being able to send emails, the application can also read and delete them.
- The application can also access any other part of the API and potentially many other APIs.
- If the application knows the username and password, then there is nothing stopping it from logging in as the user and changing the password.
Issue #2: Revocation
What if the application has been compromised? How do we revoke those credentials?
- The user will have to go and change the password. Now, what if the password was being used at other websites? While we should encourage users to use different passwords for different websites, we should not penalize them for not doing so when we make a mistake.
- So we not only do a disservice to the user, but we also break any other application using the API since the credentials they were using have now become invalid.
Issue #3: Exposed user credentials
If we store the username and password to prevent the need to ask for them every time we need access:
- It increases the API attack surface.
- The credentials will need to be stored in a reversible format within the consuming application. So instead of using a non-reversible password hashing algorithm, the app will have to
- Either encrypt it
- Or store it in plain text
Issue #4: Something you know
Because these credentials need to be repeatable, the user credentials are therefore limited to a single factor – this is something you know. Because of this, security best practices like 2FA and MFA become unavailable to us.
Issue #5: Federation
For the same reason, we also cannot federate with other companies and applications.
Functionality such as login using a Google account or login using your corporate Azure AD account would not be possible unless the identity provider also used credential sharing – which is highly unlikely in today’s day and age.
Issue #6: Incompatibilities
Collecting external credentials with good intentions is known as benevolent phishing. This method would also restrict what application types we could use.
A single page application served from a cache with no backend server would have no chance of storing these credentials securely.
(2) Cookies

Here we could redirect the user off to the API where they can enter the credentials and get a cookie. This allows the application to access the API and maybe restrict the access by having the user decide what functionality to allow. However, no matter what techniques we come up with, cookies will still be unsuitable because of:
Cross-Site Request Forgery (CSRF, aka XSRF)
When a user logs in to the API, they get a cookie. Now the application can access data on the API. However, if the user opens another tab on the browser, and tries to access the same API, they will still be authorized. This goes for any other application running in the browser as well. So instead of authorizing the application to access our API, we’ve instead authorized the browser - hence opening to a world of pain.
(3) API Keys
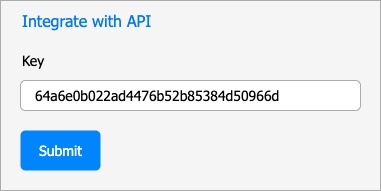
Here we ask the user to enter a key that was given to them by the API. There are many ways to implement API keys, but we are no longer exposing the user credentials to the application (Impersonation, Exposed user credentials).
We also no longer limit what authentication methods we can use in terms of factors (Something you know) and identity provider (Federation).
If we allow API keys to be generated per application, we can make key revocation much simpler (Revocation).
We can also create mechanisms to restrict permissions associated with each key to scope the key to only what the application needs.
However, while API keys solve a lot of problems of credential sharing, it still struggles with applications that cannot keep a secret.
So again if you have a single server application with no server backend, then you’re going to have problems keeping this key secure or away from the client device. (Incompatibilities)
API keys also have their own set of issues:
- No Standards: API Keys depend on the implementation. There is no standard design method in creating the API key infrastructure.
- Expiration: Long-lived. This is good from a user perspective (since we don’t want to regenerate and redistribute the API keys every few days or weeks). However, the problem is that if the key gets stolen, it could be used indefinitely until discovered.
(4) OAuth 2.0
Finally, the solution we were waiting for.
Some facts about OAuth 2.0:
- It is an authorization framework
- Built for HTTP APIs
- Has scoped access, meaning that it allows access to only certain parts of the application
- Is a delegation protocol, i.e. it allows applications to talk freely to other applications
Let’s cover the working of OAuth 2.0 in the next section.
OAuth 2.0 Players




A typical OAuth request flow
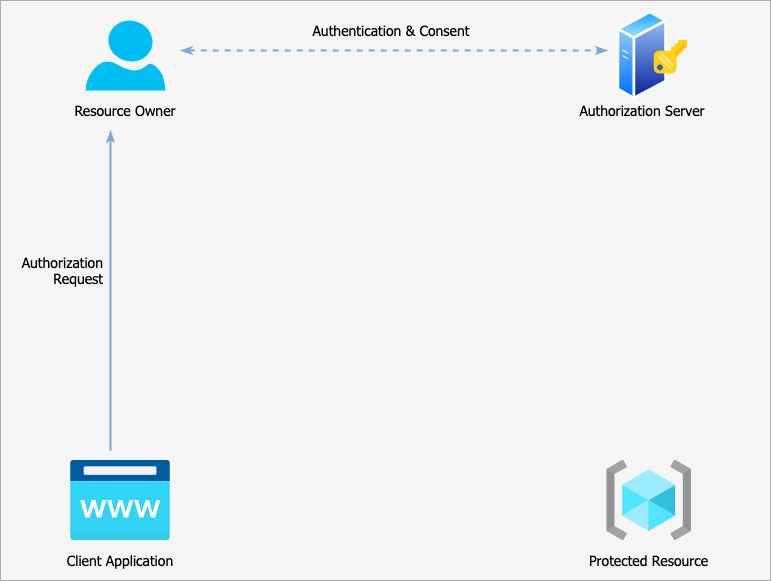
The client application sends an Authorization Request, which is granted by the Resource Owner. The Resource Owner authenticates itself on the Authorization Server and gives its consent for the application to gain access on the specified resources.
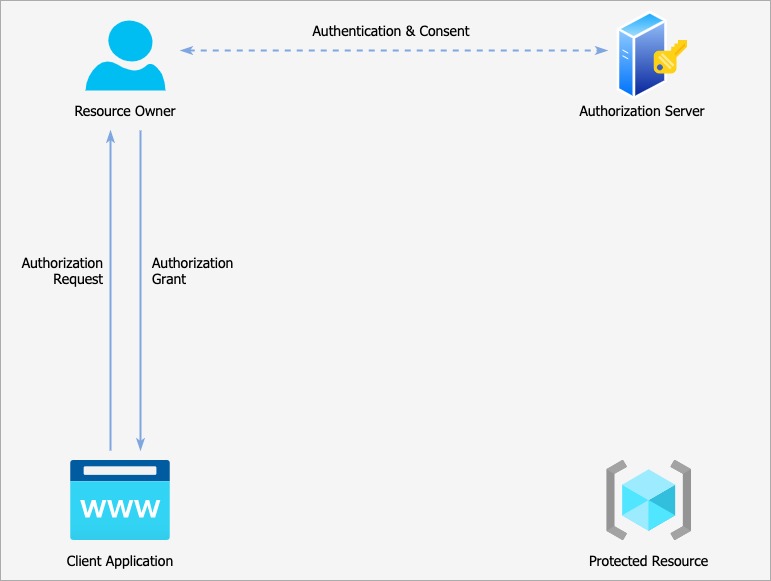
The authorization is then granted in the form of an ‘Authorization Grant’, which is nothing but a physical representation of the user’s authorization of the client application to act on their behalf in the form of a random value that only the authorization server understands.
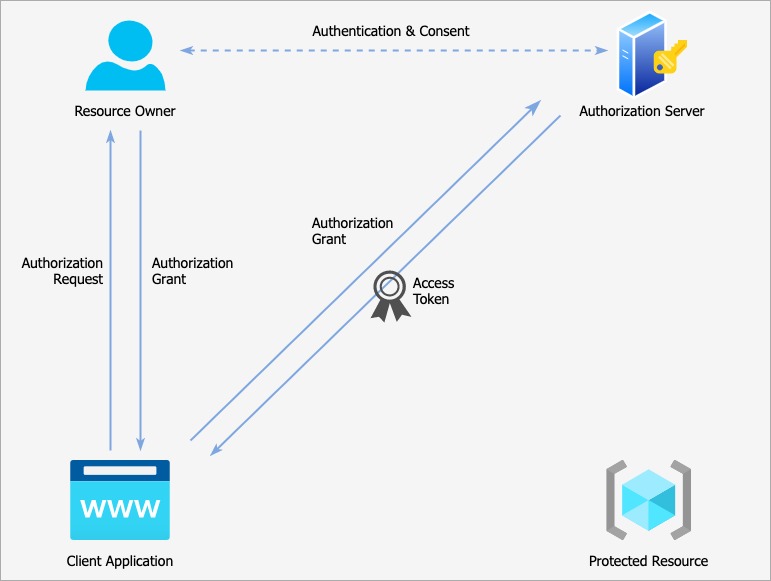
The client application then makes a backchannel request away from the browser. In this request it includes
- the authorization grant it previously received
- and also some way of authenticating itself as a valid client
If everything checks out, the Authorization Server responds with an Access Token. Only the application that was given the Authorization Grant can swap it for a token.
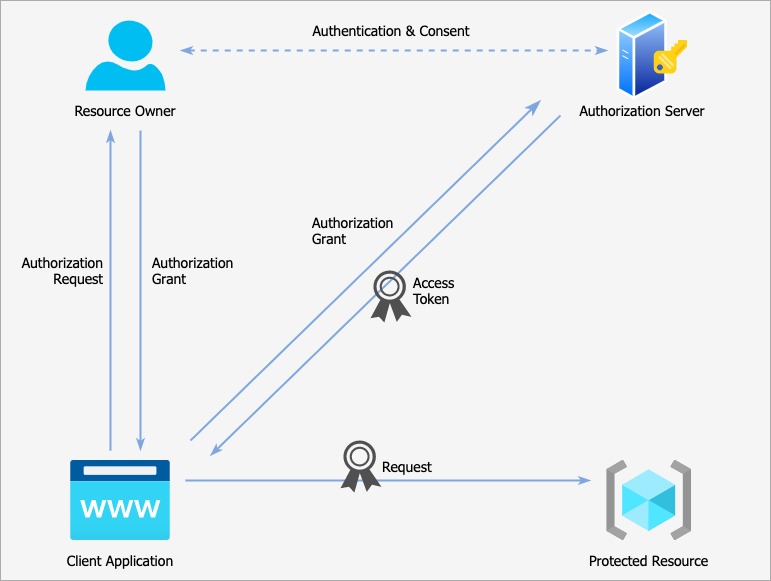
This Access Token can then be used by the client application to authorize requests to the protected resource. This is sent over using the authorization header with the scheme being defined by the Authorization Server. This is typically the bearer scheme, meaning that whoever has the Access Token can use it.
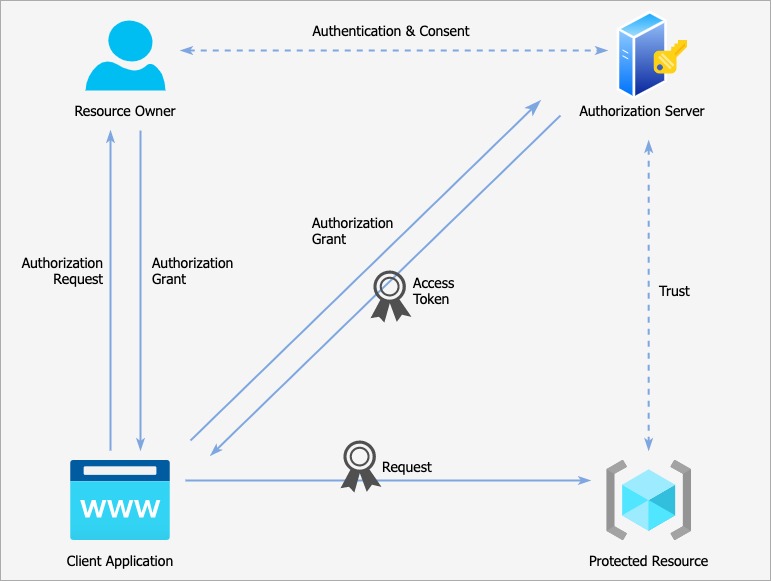
When the Protected Resource receives the bearer token, it needs to verify in some way. This is where things get a little hazy as the exact structure of an access token and its validation procedure are again outside of the OAuth specification. It could be:
- structured data e.g. JSON Web token
- or it could be completely unstructured
We could verify it within the protected resource, or we could send it to the authorization server to be validated. Either way, the protected resource must verify that the token was issued by the Authorization Server that it trusts, and then be able to understand what user made the delegation and what permissions were delegated. If everything checks out, the client application is allowed access.
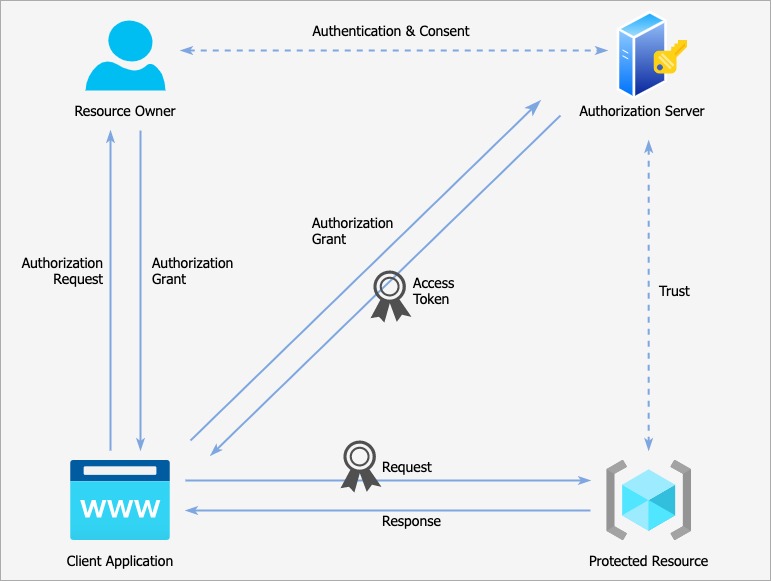
The client will now get the desired response when it sends the request to the protected resource with the access token.
Example
Consider a social coffee application called Unground, which offers the ability for the users to integrate their reward points account from a third-party company called Bitter Brew.
This is how the Unground app looks:
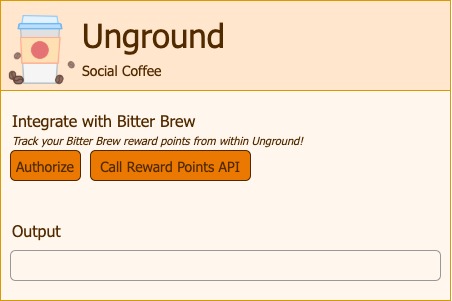
If we call the reward points API without authorization, we get a 401 unauthorized:
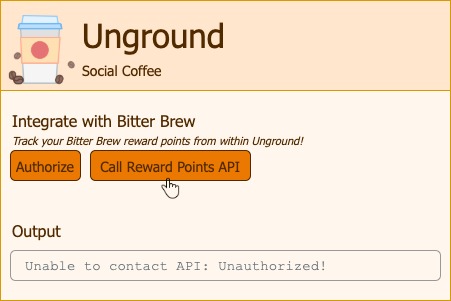
Let’s authorize first and see what happens:
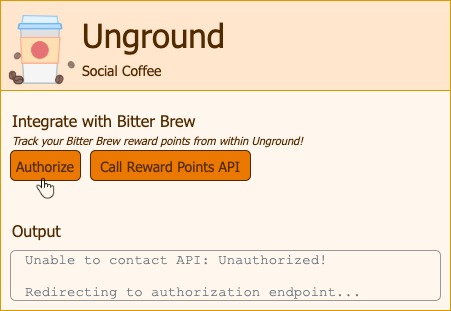
We are now redirected to the Bitter Brew authorization server:
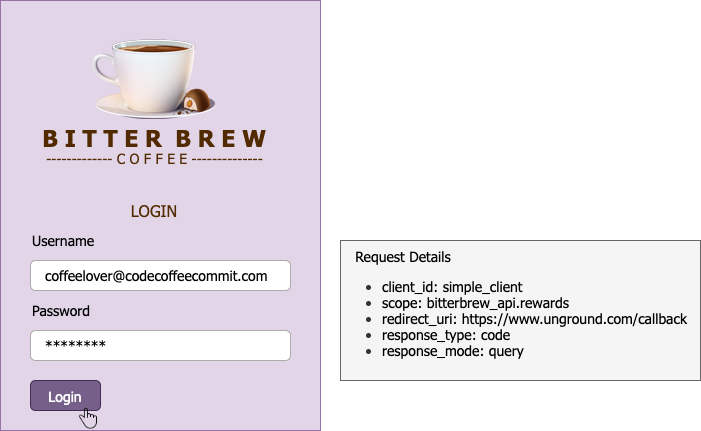
Once we authenticate, we are given the consent screen:
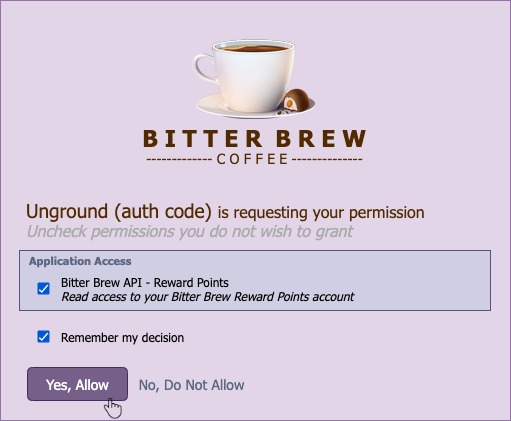
Here we are being informed of what the client application is trying to do – which in this case is to get read access to the reward points API. We are allowed to deny this request – which would simply stop the authorization process and return us to the client application.
We could pick and choose which permissions to grant, we should not be held hostage to the consent.
Once we authorize the client application, we are then returned back to our app.
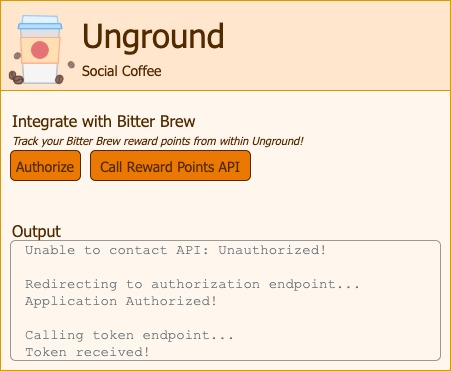
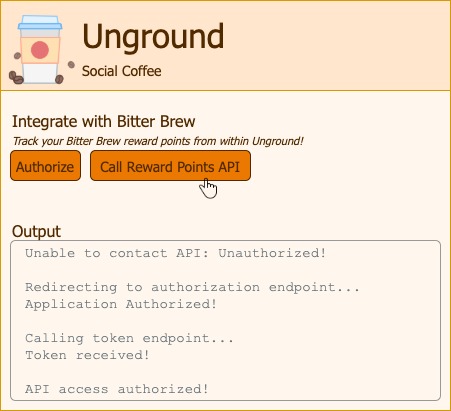
The auth grant is then swapped for a token and now Unground can call the rewards API on our behalf. Let’s try it:
Final words
OAuth got a lot of things right, by solving complex problems in a simple manner. It solved issues we saw earlier like Delegated Access, API access control, Separation of user & client credentials, and User consent.
That said, a major misconception that should be clarified is that OAuth only solves for Authorization, and not for Authentication. If there is a need for identity verification along with OAuth, OpenID Connect is one way popular way that solves the use case.
That’s it for Part 1 of the series, read the next part here to go through OAuth in detail.